
Jonas PNG Yi Wei, Prabhu Natarajan, and Ganesh Neelakanta IYER
School of Computing (SOC), National University of Singapore (NUS)
Sub-Theme
Building Technological and Community Relationships
Keywords
Retrieval-augmented generation, educational technology, AI-powered forum support, automated response evaluation
Category
Paper Presentation
Introduction and Research Context
This paper is a summarised version of a final-year project (FYP) Paper. It explores the integration of Retrieval-Augmented Generation (RAG) within educational forums to enhance automated support systems for student queries. Despite the growing interest in generative AI in education, many platforms still lack systems that effectively combine contextual retrieval with generation to provide precise, course-relevant answers. The motivation stems from the increasing demand for scalable, high-quality educational support in massive online learning platforms such as Coursemology. The extended version of this paper can be found here.
Literature Background
Retrieval-augmented Generation (Lewis et al., 2020) is a hybrid technique that improves response relevance by retrieving related context before generating an answer. Prior works like RAGAS (Es et al., 2023) and ARAGOG (Eibich et al., 2024) demonstrate the importance of evaluating factual correctness and relevance in generative systems. Additionally, studies such as Tamilmani et al. (2020) provide frameworks for understanding user acceptance of educational technologies.
Research Questions
- How effectively can RAG improve the contextuality and relevance of forum responses?
- To what extent do teaching staff accept AI-generated responses in an academic setting?
- Can automated support reduce educator workload while maintaining response quality?
Methodology
The Forum Auto Response system developed, RagWise, was architected as a loosely coupled component within Coursemology. It integrates:
- Knowledge Bases: Vector Database (PSQL with pgvector) that contains course materials’ (Lecture Notes, Assignment, Quiz, etc.) text chunks and past semesters’ forum discussions
- Custom Prompt Engineering: Structured templates and few-shot examples.
- Image Captioning: Leveraging OpenAI’s OCR for handling image-based queries.
- Automated Evaluation: Using RAGAS metrics to determine Faithfulness and Relevance scores which are used as benchmarks.
- Human in the Loop Integration: Responses with Faithfulness and Relevance Scores below a set threshold are saved as drafts, allowing teaching assistants to edit before publishing posts.
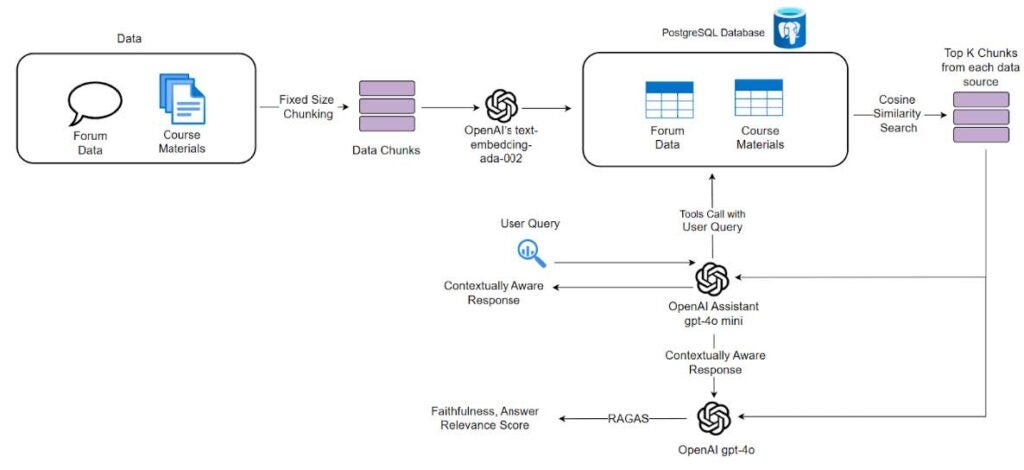
Figure 1. RagWise’s RAG workflow

.

.
Empirical Evaluation Results and Key Findings
The empirical evaluation comprised both quantitative analysis of 34 AI-generated responses with the help of Teaching Assistants (TA) from IT1244 and a qualitative survey for TA using the UTAUT2 model.

.
41.18% of AI-generated posts were used without edits, 58.82% required some edits. The word count distribution in the figure above compares the original AI-generated responses with their TA-edited versions. The near-identical curve shapes suggest that the AI-generated responses were already close to human-refined standards. This demonstrates that the AI-generated responses required only marginal adjustments, reinforcing the reliability of the RAG system in producing well-structured initial drafts. Two pairwise t-tests were conducted to evaluate the statistical significance of differences in cosine similarity between TA-edited and generated text: one comparing responses categorised into low and high answer relevance groups, and the other comparing responses categorized into low and high faithfulness groups.
Hypothesis Testing Results I
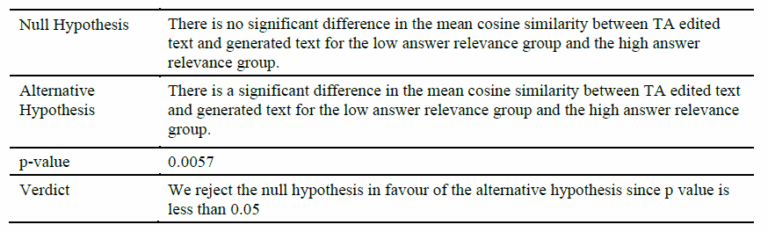
.
This suggests that generated responses with higher relevance scores undergo fewer edits compared to those with lower relevance scores. Since cosine similarity measures how closely the edited text resembles the original generated text, a higher similarity score indicates minimal modifications, whereas a lower similarity score signifies more substantial changes.
Hypothesis Testing Results II

.
This finding suggests that the extent of edits made to generated responses does not significantly differ based on faithfulness scores. In other words, responses with low faithfulness scores do not necessarily undergo more extensive edits compared to those with high faithfulness scores. The lack of significant difference suggests that even when a generated response has low faithfulness to the provided context from RAG, the LLM can still produce answers that require similar levels of editing as highly faithful responses. This indicates that language models possess substantial pre-trained knowledge and can leverage this intrinsic information to generate coherent and useful responses, even when they are not closely adhering to the provided context.
Statistical overview of teaching team survey
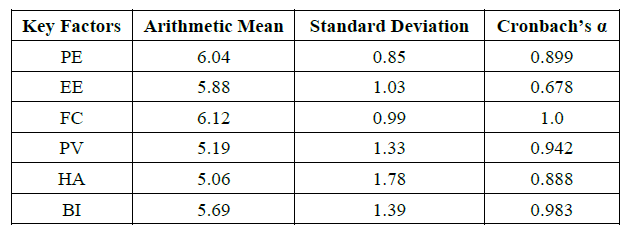
.
As observed from the above survey result, most of the constructs exhibit Cronbach’s alpha values above the generally accepted threshold of 0.70 (Taber, 2018), indicating strong internal consistency. While Effort Expectancy (EE) has an alpha value slightly below 0.70 (0.678), it remains near the acceptable range, which is often considered tolerable in exploratory studies (Hair et al., 2019). The relatively high reliability scores suggest that the Survey questions measuring each construct were well-aligned.
Looking at the arithmetic means, Facilitating Conditions scored the highest, suggesting that respondents felt well-supported by the resources and environment needed to use the RAG system effectively. Performance Expectancy also received a high mean score, implying that participants perceived the RAG system as beneficial in improving their responses and overall productivity. All instructors gave a score of 5 or higher when indicating if the RagWise System improves the quality and response time of responses to student queries on forum.
Significance and Future Work
RagWise not only demonstrated the feasibility of RAG systems in real-world academic environments but also received strong endorsements from its users. It streamlined response generation, reduced instructor load, and preserved educational quality. Its modular design allows it to be adopted in other courses, as it is slated for rollout by the Ministry of Education (MOE) for teaching computing in schools.
Future work includes:
- Exploring alternative evaluation strategies beyond RAGAS
- Experimenting with newer LLM providers and models
- Extending AI responses beyond forums such as assignment comments.
Acknowledgements
This project was made possible with the support of the Coursemology team, especially Dr. Ben Leong and Jonathan, who provided forum data and offered valuable insights related to Coursemology’s forum infrastructure.
References
Eibich, M., Nagpal, S., & Fred-Ojala, A. (2024, April 1). ARAGOG: Advanced RAG output grading. arXiv.org. https://arxiv.org/abs/2404.01037
Es, S., James, J., Espinosa-Anke, L., & Schockaert, S. (2023, September 26). RAGAS: Automated evaluation of retrieval augmented generation. arXiv.org. https://arxiv.org/abs/2309.15217
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2019). Multivariate data analysis. https://thuvienso.hoasen.edu.vn/handle/123456789/10308?locale-attribute=vi
Lewis, P. S. H., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W. T., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Neural Information Processing Systems, 33, 9459–9474. https://proceedings.neurips.cc/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf
Taber, K. S. (2018). The use of Cronbach’s Alpha when developing and reporting research instruments in science education. Research in Science Education, 48, 1273-1296. – References – Scientific Research Publishing. (n.d.). https://www.scirp.org/reference/referencespapers?referenceid=3681582
Tamilmani, K., Rana, N. P., Wamba, S. F., & Dwivedi, R. (2020). The extended Unified Theory of Acceptance and Use of Technology (UTAUT2): A systematic literature review and theory evaluation. International Journal of Information Management, 57, 102269. https://doi.org/10.1016/j.ijinfomgt.2020.102269

































































